TOC
People discuss the most efficient way to manage text files for several reasons: apart from programming, someone wants to build a digitalized notebook for new knowledge; Someone wants to manage the increasing case files in office work; Someone wants to archive thousands of articles they hoard on the internet. Either way, I call that ‘text digesting system’ or ‘personal wiki’. Buckle up, I got some strong opinions about this topic.
I think we all have been struggling in choosing tools: some excel at supporting markdown (pycharm, Rstudio), some are good at coding highlighting (VS code, Notepad++), some support real-time online collaboration (Overleaf, Github) or even text searching in images (MS Onenote, Goodnotes in Apple). If one has not used Emacs, I would probably recommend Evernote or Onenote. But if you are an Emacs user, this is the chance of tasting the one-for-all solution.
Caveat: this image is an extremly personal experience based summary of the tool learning curve: 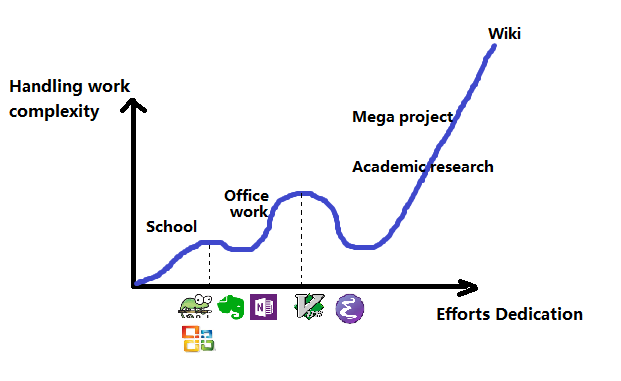
On methodological level, my argument of recommending is that Emacs is the tool which has the most potential to facilitate you to manage all level of text work: from a TODO shopping list to a one-person Wikipedia.
On technical level, Emacs org-mode meets different needs with all types of packages. For example:
• To take note speech: input in org-mode
• To memorize knowledge: Anki + Anki-editor
• To classify: categories and tags
• To search: helm-ag + regex
• To visualize structure: Knowledge Graph; Daft; NotDeft; etc.
• To present in slides: Org-reveal
• To generate static website: Hugo + Ox-hugo
0. General opinion
Although as many merits mentioned above, Emacs is a tool which takes years to master, so I would NOT recommend converting to Emacs right after watching some killer demo. Instead, my general opinion about text work is keeping different stage of work in different places, for non-proficient Emacers.
Firstly, put speedy notes in out-of-boxes softwares in corresponding area (e.g. put text/snapshot/recordings in Onenote; put R code in Rstudio, put math paper in Lyx; draw figure in paint) Capturing ideas and finishing work at this stage is much more important than debugging Emacs. Secondly, constantly review the work you’re managing and do this in Emacs. It will not only help you to know Emacs, to learn using different backend, but also facilitates you to extract your own perception out of the hoarded files collected. As a consequence, this entitles you with one particular advantage that you will be maintaining a database of intellectural work on standby for you to present anytime, in an overwhelmingly good way.
1. Text search and classification
Softwares like Evernote or Onenote is excellent in most daily work. Skepticism emerges in three common cases: 1). when there is increasing reptitive text processing work (e.g. using yasnippet). 2). when there is needs for higher level of efficiency (e.g. version control, regular expression based search). 3). when there is needs for variety exporation (e.g.HTML or Latex). These happens regardless of managing several files or managing over a thousand files, which adds together became the reason that I moved my text work to Emacs.
For example, the most common way to manage files is using categories and tags (or tweaked as pages/binders/etc.) The limitation of using category is that you can only allocate an article ONCE (what about articles inherently belong to two or more categories?). The tags seem to help address this issue, and yet I noticed it’s still not enough in practical work. This is also the reason that people started using some other tools and switched back to Emacs in the end.
My opinion is that: the classification of an article should be better decided by the *whole article*, rather than several keywords.
After a long while of managing hundred notes, I noticed the most frequently used (and
efficient) function is =global search =. I still use categories and tags,but
that’s just to maintain my overview of the structure of all articles.
I use helm-ag, the silver search which is a searcher reconstructed with C and
it’s SO FAST, especially in large files or codes with over 400,000 lines.
The linux command line search tool speed ranks as: ag > pt > ack > grep.
Acorrding to requent users, the ag search is 5-10 times faster than ack on average.
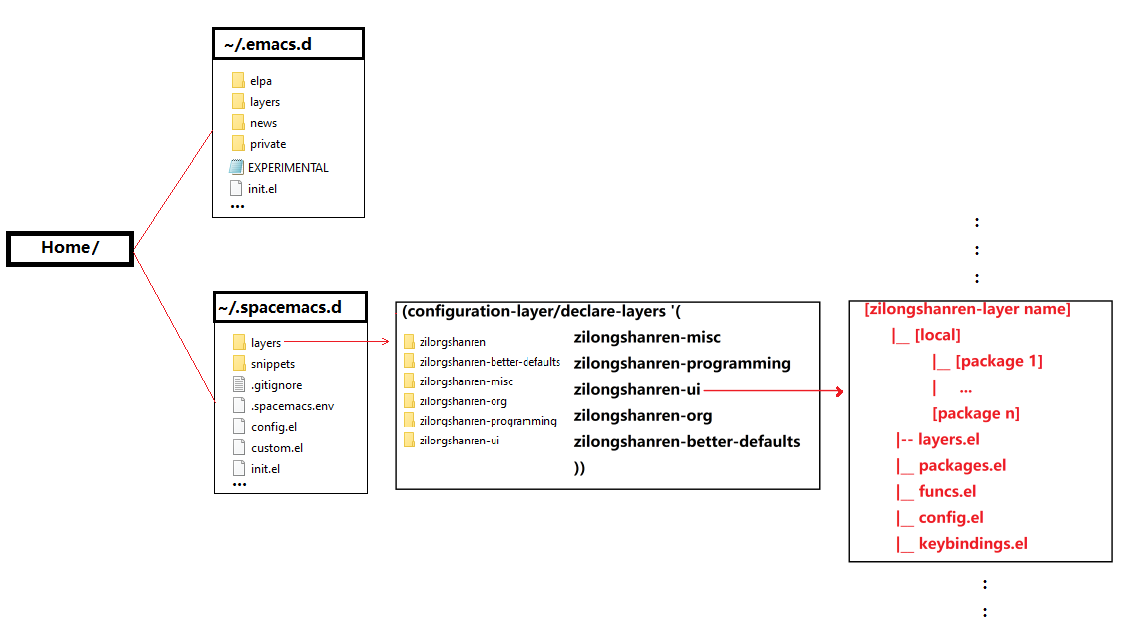
This is my spacemacs config file, which is a big text file tree that I
need to comb through constantly.
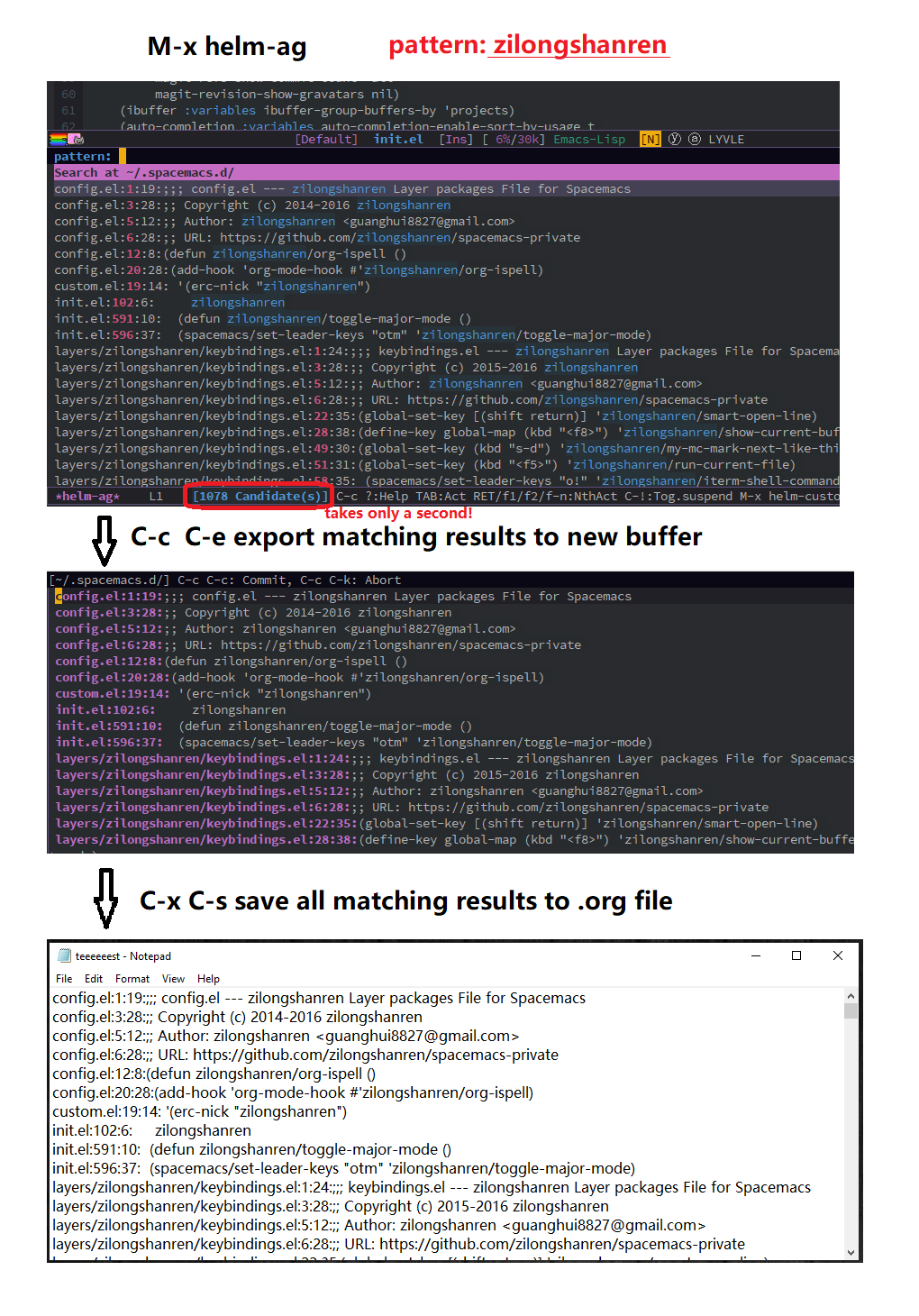
M-x helm-ag ("path-to-file") enables text search. Without path parameter, it
searches all files under parent file of current buffer. For example,
searching zilongshanren in ~/.spacemacs.d/init.el buffer.
2. Structure visualization
Org-mode seems to encourage or intentionally facilitate you organize text articles in ONE file. For example, all this website is written in one file with different categories to distinguish taxonomy. All the org-capture facilitated items such as to-do or blog idea is managed in a single file.
In this case there are lots of software you can use to illustrate the in-file structure.
Check this: Intro to Mindmap, Gantt Chart, Graphviz - http://ergoemacs.org/
3. Knowledge graph
This is for cases where you want lots of cross-references on files may be in different directories:
Semantic Synchrony, ultrafast video demo - YouTube - https://www.youtube.com/ A video introduction to Semantic Synchrony · synchrony/smsn Wiki - https://github.com/
4. Anki
I have written a separate article of Anki in this blog: Using Anki-editor to build flashcard in Emacs Org-mode
comments powered by Disqus